Pipeline
Here we outline the work steps we followed to answer the questions in our problem statement. In the first subsection, we cover two initial setup tasks that prepare the data for the rest of the pipeline:
- Translating CVs from Italian into English so we can apply semantic-matching techniques consistently.
- Labeling with an LLM each parser extracted skill as either hard or soft.
🔗 See the Hard Soft skills labelling notebook
With these preparations in place, our pipeline we built is divided into the following steps:
Data Cleaning
We standardized and filtered the raw, anonymized CV texts with structural issues as:- Empty / Whitespace-Only/ Very Short Text
- High Repetition
- Low token & vocabulary Richness
- Corrupted CVs with a fraction of invalid characters
- CVs with Placeholder Tails (e.g. “XXXXXXXXXX…”)
- CVs with Poor Translations
Parsed skills of the candidates with corrupted CVs has been also excluded.
The candidates’ demographic data (age, gender, and geographic location) were then analyzed to uncover any potential correlations or redundancies among the features.
Exploratory Analysis
Once the data had been cleaned, we conducted an exploratory analysis of the skills extracted by the parser, focusing on:- Distribution of parsed skills and job information : explore how different skills are distributed across roles and sectors.
- Skills per candidate distribution: analyze the number of skills each candidate has, flagging any outliers.
- Hard vs. soft skills: examine and compare the distributions of hard skills versus soft skills.
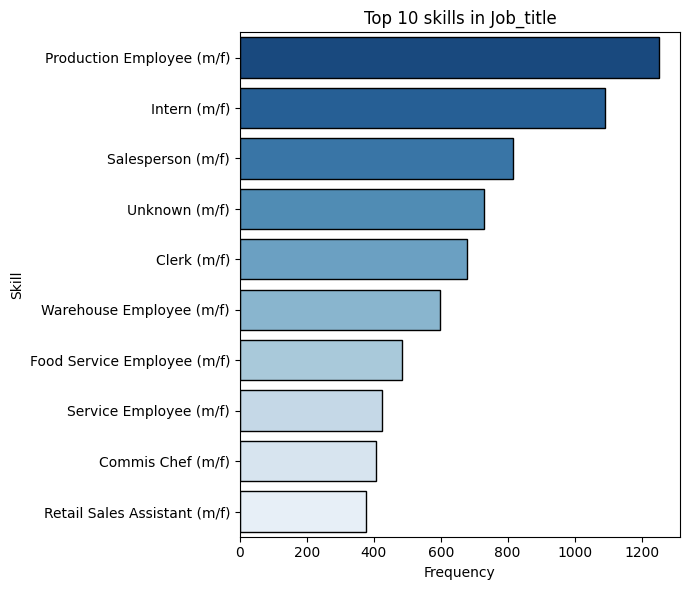
Distributions Analysis
This analysis aims to uncover distributional imbalances in the parsed skills by considering the following demographic data:
- Gender
- Location
- Hard vs. soft skills
To quantify these imbalances, we have defined disparity metrics such as the Gini index and a custom bias strength measure.
Why This Matters:
Detecting these imbalances is critical to designing a robust, fair pipeline that flags biases introduced by the CV parser relying only on raw CV inputs and their parsed outputs.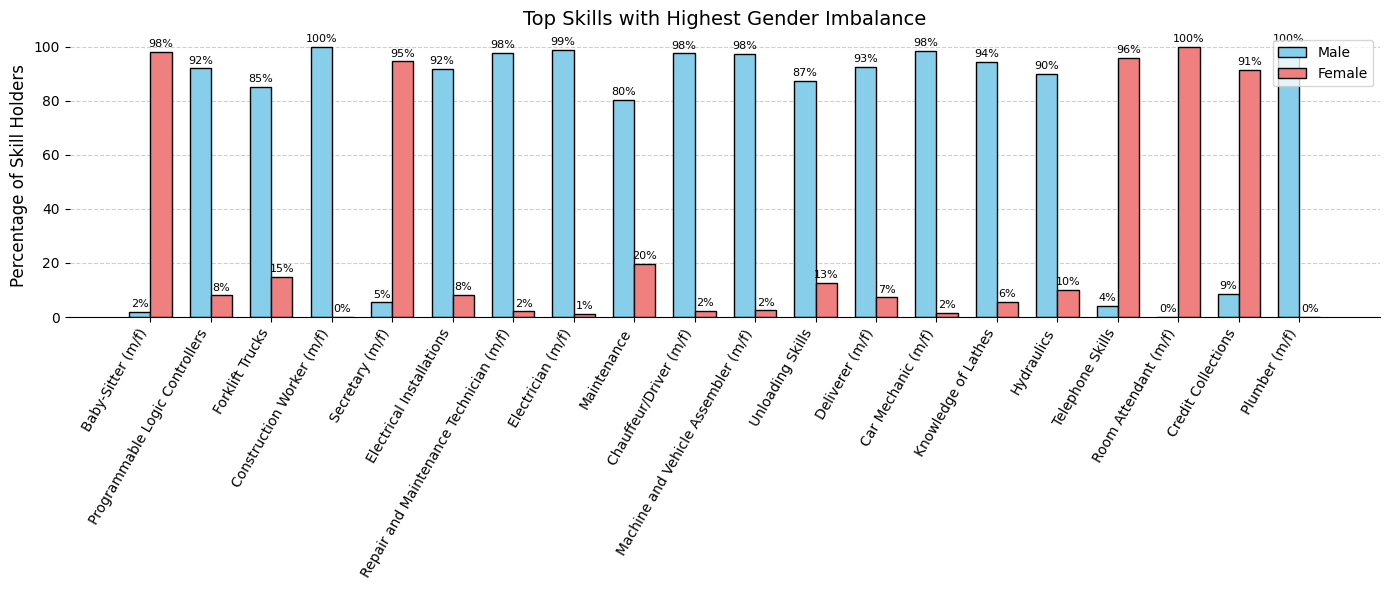
Bias Detection
After analyzing the various imbalances in the distributions of skills extracted by the parser, we tackled bias detection through a hybrid pipeline:
- On the skills side (specifically DRIVERSLIC and LANGUAGE_SKILL), we implemented a regex-based extractor that systematically scans each CV for patterns associated with driving licenses and language proficiencies, ensuring we capture every variant and format used by candidates.
- On the job-title side, we deployed a two-step process:
- Rule-based: exact matching against the official ESCO european job list (link), pulling in any titles that appear in the raw CV text.
- Semantic matching: catches synonyms or paraphrases of the same job experience, making our extraction robust to differences in how the parser names each job.
eg. ESCO: Postman, Parsed skill: Postal operator, Similarity: 0.64
Using our pipeline results as the ground truth, we measured the overall performance of the proprietary parser by comparing its outputs against our method and analyzing their agreement.
We focused on false negatives, candidates for whom our extractor found a match but the parser returned nothing, by choosing a regex that ensures a high precision.
To make these insights more accessible, we built a Streamlit app that lets you dive into individual candidates. For each false negative, the interface on the left displays the raw CV text with regex matched segments highlighted in red and on the right shows the skills the parser actually assigned to that candidate.
After applying the pipeline to the skills mentioned above and observing numerous discrepancies between the parser and our extraction method, we conducted a bias assessment across three groups (gender, geographic location, and CV length) to determine whether parser errors disproportionately affect under or over represented populations.