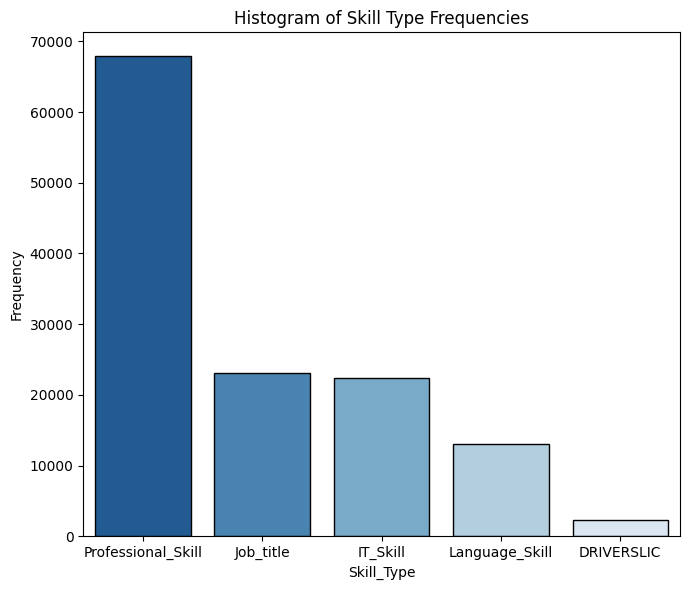
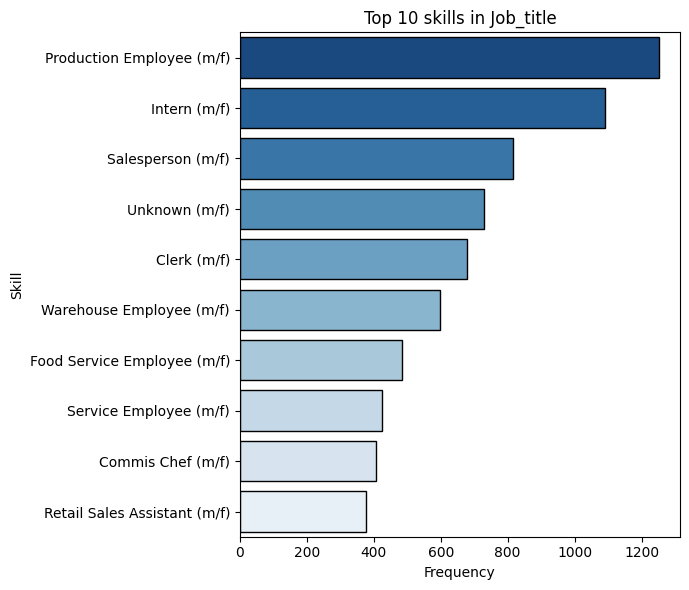
This function shows the most common <skills> for candidates who have a specific <job_title>. It simply:
Picks out all candidates with the chosen job title.
Collects their skills of the specified category.
Counts how often each skill appears.
Plots the top n skills by frequency.
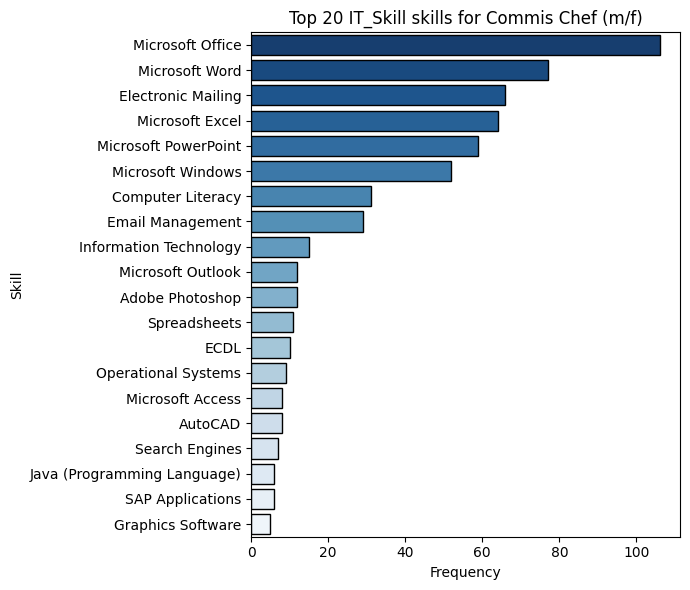
With the parameters below, we are displaying the top 20 most frequent IT skills among candidates with “Commis Chef (m/f)” job experience.
plot_top_skills_for_job_title(cv_skills, "Commis Chef (m/f)", "IT_Skill", top_n=20)
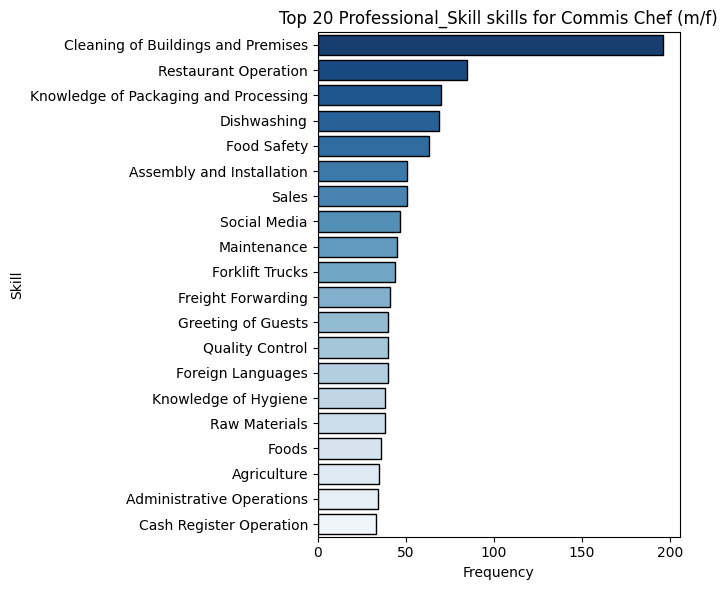
plot_top_skills_for_job_title( cv_skills, "Commis Chef (m/f)", "Professional_Skill", top_n=20)
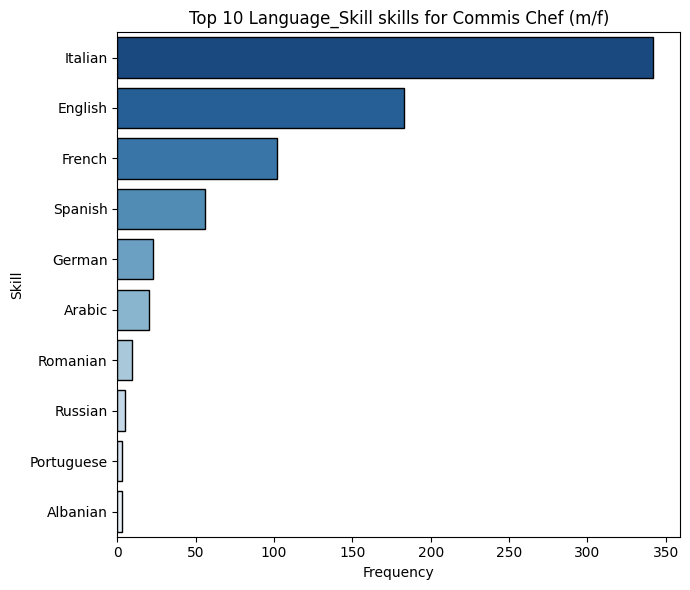
plot_top_skills_for_job_title( cv_skills, "Commis Chef (m/f)", "Language_Skill", top_n=10)
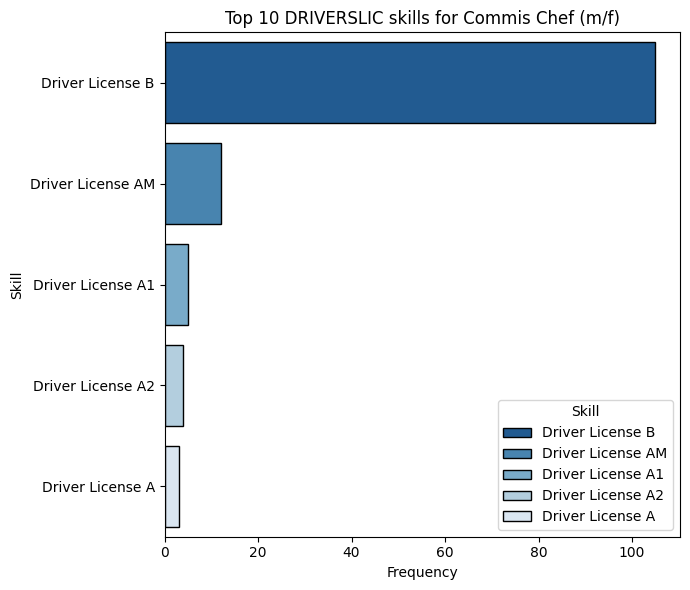
plot_top_skills_for_job_title(cv_skills, "Commis Chef (m/f)", "DRIVERSLIC", top_n=10)
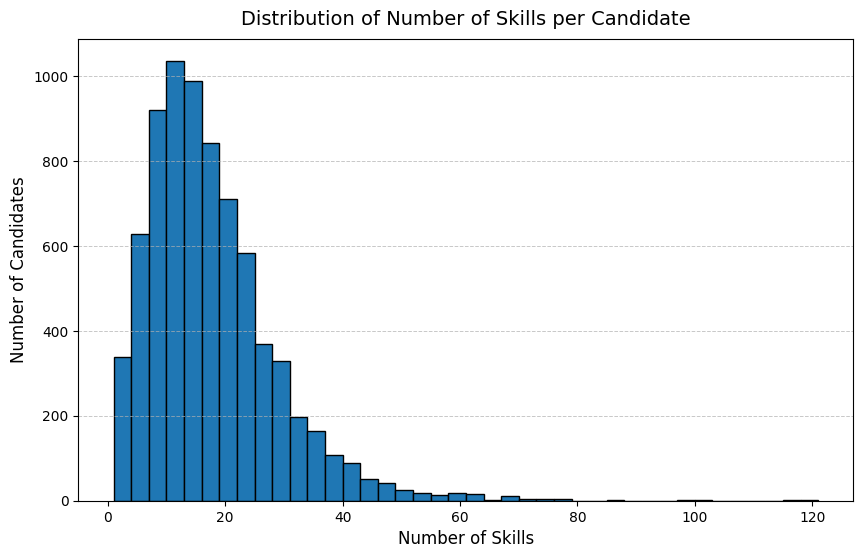
Counting Skills per Candidate
In this step, we aim to:
Visualize the distribution of the number of skills extracted per candidate.
Spot and investigate outliers, candidates who list an unusually high number of skills.
skill_counts = cv_skills.group_by("CANDIDATE_ID").len()fig, ax = plt.subplots(figsize=(10, 6))ax.hist(skill_counts["len"], bins=40, edgecolor="black")ax.set_title("Distribution of Number of Skills per Candidate", fontsize=14, pad=10)ax.set_xlabel("Number of Skills", fontsize=12)ax.set_ylabel("Number of Candidates", fontsize=12)ax.grid(axis="y", linestyle="--", linewidth=0.7, alpha=0.7)
plot_boxplot( data=skill_counts["len"], labels=None, title="Boxplot of Skills per Candidate", xlabel="Number of Skills", colors=["orange"], figsize=(10, 2),)
Hard vs Soft Skills Analysis
In this section, we investigate the distribution of hard and soft skills extracted from the candidate CVs. (column Professional_Skill)
The logic used to label each skill as hard or soft is documented in the hard_soft_labelling.ipynb notebook.
Here we present:
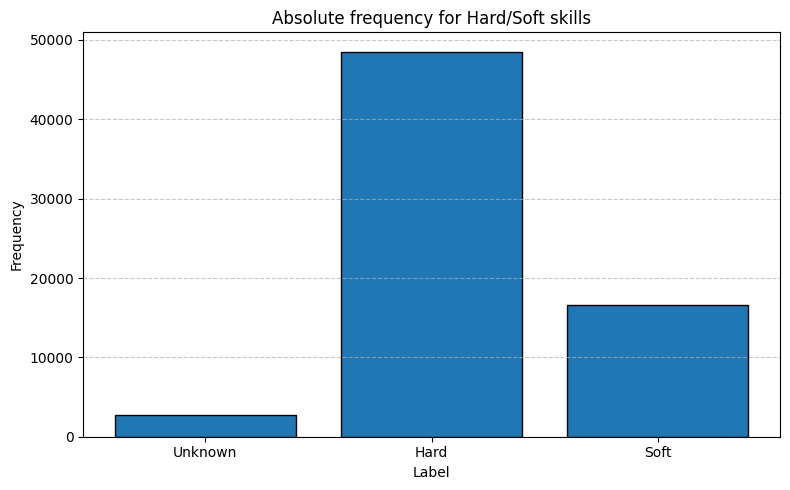
Total distribution of hard vs soft skills across all candidates.
Distribution per candidate: number of hard vs soft skills per individual, to highlight representation gaps.
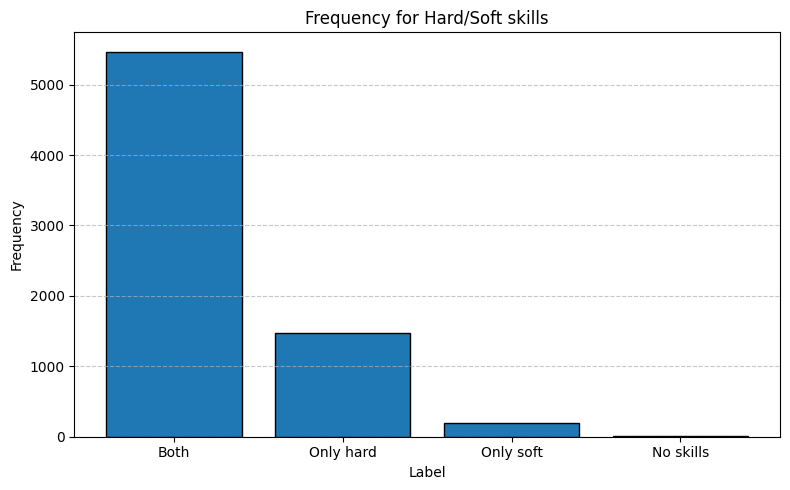
Hard skills dominate the dataset, accounting for roughly ~75% of all skills extracted from the CVs.
Soft skills are markedly under represented, at about one skill in five.
Small remainder: we classified as “Unknown” terms that did not match either taxonomy, highlighting the presence of noise in the parsed skills data. (see hard_soft_labelling.ipynb)
counts = cv_skills_with_label["label"].value_counts()plot_distribution_bar( counts,"label","count","Label","Frequency","Absolute frequency for Hard/Soft skills",)
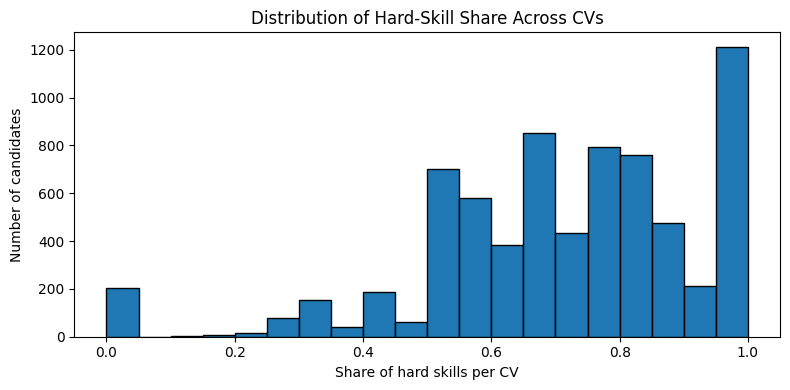
The chart shows how technical competences (hard skills) are distributed across each candidate.
For each one of them we calculate the hard skill share, the ratio between the number of hard skills and the total number of skills, listed (hard + soft + any unknown items) and we plot all of these percentages in a histogram.
data = per_cand["hard_share"].to_numpy()plt.figure(figsize=(8, 4))plt.hist(data, bins=20, edgecolor="black")plt.xlabel("Share of hard skills per CV")plt.ylabel("Number of candidates")plt.title("Distribution of Hard-Skill Share Across CVs")plt.tight_layout()plt.show()
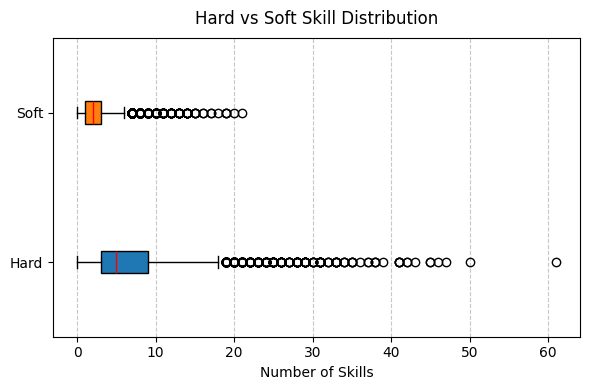
The box plot highlights several outliers. (20+ hard skills / 10+ soft skills)
Such counts are well beyond the typical range and may indicate parsing errors (e.g bullet points misclassified as skills, the same skill split into multiple tokens ecc). These outliers should be reviewed manually to confirm whether they reflect unusually rich profiles or artefacts produced by the parsing pipeline.
plot_boxplot( data=[per_cand["Hard"], per_cand["Soft"]], labels=["Hard", "Soft"], title="Hard vs Soft Skill Distribution", xlabel="Number of Skills", colors=["#1f77b4", "#ff7f0e"], figsize=(6, 4),)